Python爬虫——爬取豆瓣电影Top250代码实例
(编辑:jimmy 日期: 2024/5/9 浏览:3 次 )
利用python爬取豆瓣电影Top250的相关信息,包括电影详情链接,图片链接,影片中文名,影片外国名,评分,评价数,概况,导演,主演,年份,地区,类别这12项内容,然后将爬取的信息写入Excel表中。基本上爬取结果还是挺好的。具体代码如下:
#!/usr/bin/python
#-*- coding: utf-8 -*-
import sys
reload(sys)
sys.setdefaultencoding('utf8')
from bs4 import BeautifulSoup
import re
import urllib2
import xlwt
#得到页面全部内容
def askURL(url):
request = urllib2.Request(url)#发送请求
try:
response = urllib2.urlopen(request)#取得响应
html= response.read()#获取网页内容
#print html
except urllib2.URLError, e:
if hasattr(e,"code"):
print e.code
if hasattr(e,"reason"):
print e.reason
return html
#获取相关内容
def getData(baseurl):
findLink=re.compile(r'<a href="(.*" rel="external nofollow" >')#找到影片详情链接
findImgSrc=re.compile(r'<img.*src="/UploadFiles/2021-04-08/(.*jpg)">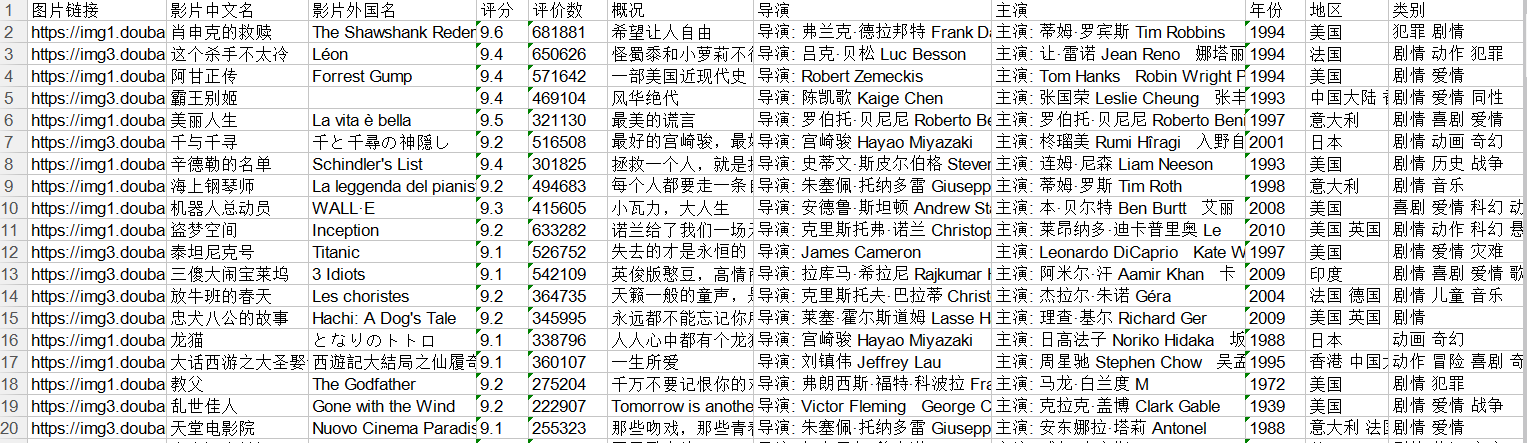
以上所述是小编给大家介绍的Python爬取豆瓣电影Top250实例详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对网站的支持!

下一篇:详解python数据结构和算法