浅析SQL Server中的执行计划缓存(上)
简介
我们平时所写的SQL语句本质只是获取数据的逻辑,而不是获取数据的物理路径。当我们写的SQL语句传到SQL Server的时候,查询分析器会将语句依次进行解析(Parse)、绑定(Bind)、查询优化(Optimization,有时候也被称为简化)、执行(Execution)。除去执行步骤外,前三个步骤之后就生成了执行计划,也就是SQL Server按照该计划获取物理数据方式,最后执行步骤按照执行计划执行查询从而获得结果。但查询优化器不是本篇的重点,本篇文章主要讲述查询优化器在生成执行计划之后,缓存执行计划的相关机制以及常见问题。
为什么需要执行计划缓存
从简介中我们知道,生成执行计划的过程步骤所占的比例众多,会消耗掉各CPU和内存资源。而实际上,查询优化器生成执行计划要做更多的工作,大概分为3部分:
首先,根据传入的查询语句文本,解析表名称、存储过程名称、视图名称等。然后基于逻辑数据操作生成代表查询文本的树。
第二步是优化和简化,比如说将子查询转换成对等的连接、优先应用过滤条件、删除不必要的连接(比如说有索引,可能不需要引用原表)等。
第三步根据数据库中的统计信息,进行基于成本(Cost-based)的评估。
上面三个步骤完成之后,才会生成多个候选执行计划。虽然我们的SQL语句逻辑上只有一个,但是符合这个逻辑顺序的物理获取数据的顺序却可以有多条,打个比方,你希望从北京到上海,即可以做高铁,也可以做飞机,但从北京到上海这个描述是逻辑描述,具体怎么实现路径有多条。那让我们再看一个SQL Server中的举例,比如代码清单1中的查询。
SELECT * FROM A INNER JOIN B ON a.a=b.b INNER JOIN C ON c.c=a.a
代码清单1.
对于该查询来说,无论A先Inner join B还是B先Inner Join C,结果都是一样的,因此可以生成多个执行计划,但一个基本原则是SQL Server不一定会选择最好的执行计划,而是选择足够好的计划,这是由于评估所有的执行计划的成本所消耗的成本不应该过大。最终,SQL Server会根据数据的基数和每一步所消耗的CPU和IO的成本来评估执行计划的成本,所以执行计划的选择重度依赖于统计信息,关于统计信息的相关内容,我就不细说了。
对于前面查询分析器生成执行计划的过程不难看出,该步骤消耗的资源成本也是惊人的。因此当同样的查询执行一次以后,将其缓存起来将会大大减少执行计划的编译,从而提高效率,这就是执行计划缓存存在的初衷。
执行计划所缓存的对象
执行计划所缓存的对象分为4类,分别是:
编译后的计划:编译的执行计划和执行计划的关系就和MSIL和C#的关系一样。
执行上下文:在执行编译的计划时,会有上下文环境。因为编译的计划可以被多个用户共享,但查询需要存储SET信息以及本地变量的值等,因此上下文环境需要对应执行计划进行关联。执行上下文也被称为Executable Plan。
游标:存储的游标状态类似于执行上下文和编译的计划的关系。游标本身只能被某个连接使用,但游标关联的执行计划可以被多个用户共享。
代数树:代数树(也被称为解析树)代表着查询文本。正如我们之前所说,查询分析器不会直接引用查询文本,而是代数树。这里或许你会有疑问,代数树用于生成执行计划,这里还缓存代数树干毛啊?这是因为视图、Default、约束可能会被不同查询重复使用,将这些对象的代数树缓存起来省去了解析的过程。
比如说我们可以通过dm_exec_cached_plans这个DMV找到被缓存的执行计划,如图1所示。

图1.被缓存的执行计划
那究竟这几类对象缓存所占用的内存相关信息该怎么看呢?我们可以通过dm_os_memory_cache_counters这个DMV看到,上述几类被缓存的对象如图2所示。

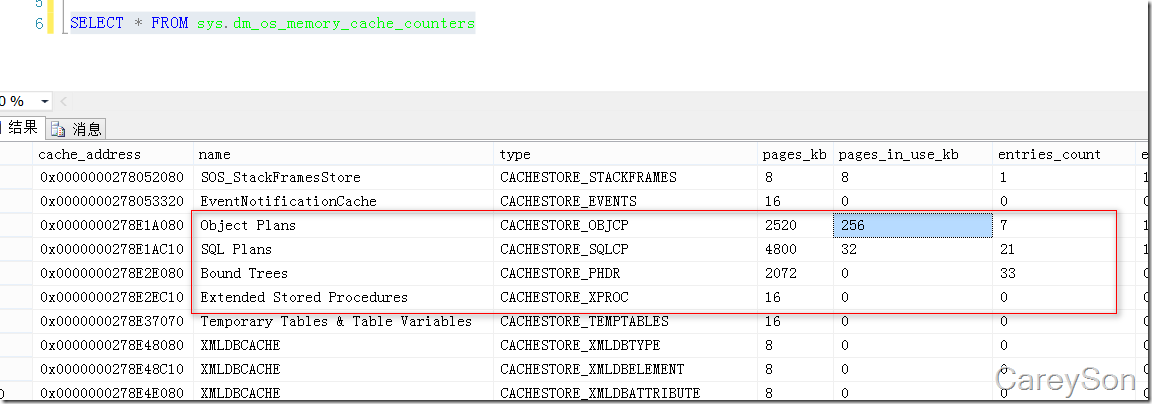
图2.在内存中这几类对象缓存所占用的内存
另外,执行计划缓存是一种缓存。而缓存中的对象会根据算法被替换掉。对于执行计划缓存来说,被替换的算法主要是基于内存压力。而内存压力会被分为两种,既内部压力和外部压力。外部压力是由于Buffer Pool的可用空间降到某一临界值(该临界值会根据物理内存的大小而不同,如果设置了最大内存则根据最大内存来)。内部压力是由于执行计划缓存中的对象超过某一个阈值,比如说32位的SQL Server该阈值为40000,而64位中该值被提升到了160000。
这里重点说一下,缓存的标识符是查询语句本身,因此select * from SchemaName.TableName和Select * from TableName虽然效果一致,但需要缓存两份执行计划,所以一个Best Practice是在引用表名称和以及其他对象的名称时,请带上架构名称。
基于被缓存的执行计划对语句进行调优
被缓存的执行计划所存储的内容非常丰富,不仅仅包括被缓存的执行计划、语句,还包括被缓存执行计划的统计信息,比如说CPU的使用、等待时间等。但这里值得注意的是,这里的统计只算执行时间,而不算编译时间。比如说我们可以利用代码清单2中的代码根据被缓存的执行计划找到数据库中耗时最长的20个查询语句。
SET TRANSACTION ISOLATION LEVEL READ UNCOMMITTED
SELECT TOP 20
CAST(qs.total_elapsed_time / 1000000.0 AS DECIMAL(28, 2))
AS [Total Duration (s)]
, CAST(qs.total_worker_time * 100.0 / qs.total_elapsed_time
AS DECIMAL(28, 2)) AS [% CPU]
, CAST((qs.total_elapsed_time - qs.total_worker_time)* 100.0 /
qs.total_elapsed_time AS DECIMAL(28, 2)) AS [% Waiting]
, qs.execution_count
, CAST(qs.total_elapsed_time / 1000000.0 / qs.execution_count
AS DECIMAL(28, 2)) AS [Average Duration (s)]
, SUBSTRING (qt.text,(qs.statement_start_offset/2) + 1,
((CASE WHEN qs.statement_end_offset = -1
THEN LEN(CONVERT(NVARCHAR(MAX), qt.text)) * 2
ELSE qs.statement_end_offset
END - qs.statement_start_offset)/2) + 1) AS [Individual Query
, qt.text AS [Parent Query]
, DB_NAME(qt.dbid) AS DatabaseName
, qp.query_plan
FROM sys.dm_exec_query_stats qs
CROSS APPLY sys.dm_exec_sql_text(qs.sql_handle) as qt
CROSS APPLY sys.dm_exec_query_plan(qs.plan_handle) qp
WHERE qs.total_elapsed_time > 0
ORDER BY qs.total_elapsed_time DESC
代码清单2.通过执行计划缓存找到数据库总耗时最长的20个查询语句
上面的语句您可以修改Order By来根据不同的条件找到你希望找到的语句,这里就不再细说了。
相比较于无论是服务端Trace还是客户端的Profiler,该方法有一定优势,如果通过捕捉Trace再分析的话,不仅费时费力,还会给服务器带来额外的开销,通过该方法找到耗时的查询语句就会简单很多。但是该统计仅仅基于上次实例重启或者没有运行DBCC FreeProcCache之后。但该方法也有一些弊端,比如说:
类似索引重建、更新统计信息这类语句是不缓存的,而这些语句成本会非常高。
缓存可能随时会被替换掉,因此该方法无法看到不再缓存中的语句。
该统计信息只能看到执行成本,无法看到编译成本。
没有参数化的缓存可能同一个语句呈现不同的执行计划,因此出现不同的缓存,在这种情况下统计信息无法累计,可能造成不是很准确。
执行计划缓存和查询优化器的矛盾
还记得我们之前所说的吗,执行计划的编译和选择分为三步,其中前两步仅仅根据查询语句和表等对象的metadata,在执行计划选择的阶段要重度依赖于统计信息,因此同一个语句仅仅是参数的不同,查询优化器就会产生不同的执行计划,比如说我们来看一个简单的例子,如图3所示。

图3.仅仅是由于不同的参数,查询优化器选择不同的执行计划
大家可能会觉得,这不是挺好的嘛,根据参数产生不同的执行计划。那让我们再考虑一个问题,如果将上面的查询放到一个存储过程中,参数不能被直接嗅探到,当第一个执行计划被缓存后,第二次执行会复用第一次的执行计划!虽然免去了编译时间,但不好的执行计划所消耗的成本会更高!让我们来看这个例子,如图4所示。

图4.不同的参数,却是完全一样的执行计划!

再让我们看同一个例子,把执行顺序颠倒后,如图5所示。
图5.执行计划完全变了
我们看到,第二次执行的语句,完全复用了第一次的执行计划。那总会有一个查询牺牲。比如说当参数为4时会有5000多条,此时索引扫描应该最高效,但图4却复用了上一个执行计划,使用了5000多次查找!!!这无疑是低效率的。而且这种情况出现会非常让DBA迷茫,因为在缓存中的执行计划不可控,缓存中的对象随时可能被删除,谁先执行谁后执行产生的性能问题往往也让DBA头疼。
由这个例子我们看出,查询优化器希望尽可能选择高效的执行计划,而执行计划缓存却希望尽可能的重用缓存,这两种机制在某些情况会产生冲突。
在下篇文章中,我们将会继续来看由于执行计划缓存和查询分析器的冲突,以及编译执行计划所带来的常见问题和解决方案。
小结
本篇文章中,我们简单讲述了查询优化器生成执行计划的过程,以及执行计划缓存的机制。当查询优化器和执行计划缓存以某种不好的情况交汇时,将产生一些问题。在下篇文章中,我们会继续探索SQL Server中的执行计划缓存。
以上内容是小编给大家介绍的SQL Server中的执行计划缓存(上)的全部叙述,希望大家喜欢。
下一篇:SQL Report Builder 报表里面的常见问题分析