基于LSTM的二进制代码相似性检测
前言
近年来自然语言处理的快速发展,推出了一系列相关的算法和模型。比如用于处理序列化数据的RNN循环神经网络、LSTM长短期记忆网络、GRU门控循环单元网络等,以及用于计算词嵌入的word2vec、ELMo和BERT预训练模型等。近几年也出现了一些论文研究这些模型和算法在二进制代码相似性分析上的应用,可以实现跨平台的二进制代码相似性检测。本文根据上述模型和算法实现了一个基于word2vec和LSTM的简单模型用于判断两个函数或者两个指令序列是否相似。
总体框架

图1.PNG
函数嵌入
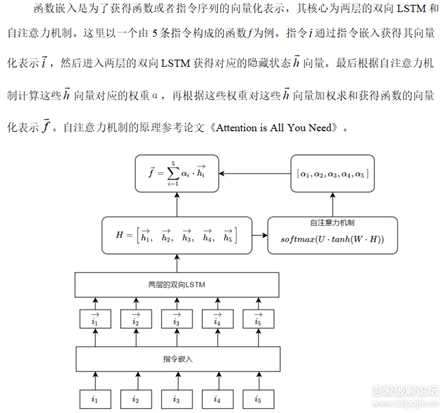
图2.PNG
LSTM是RNN的一个变体,由于RNN容易梯度消失无法处理长期依赖的问题。LSTM在RNN的基础上增加了门结构,分别是输入门、输出门和遗忘门,在一定程度上可以解决梯度消失的问题,学习长期依赖信息。LSTM的结构如下: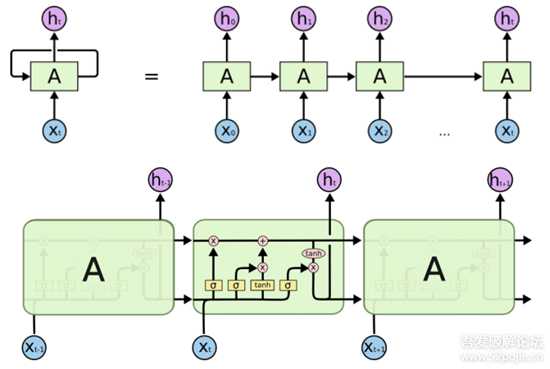
图3.PNG
运算规则如下: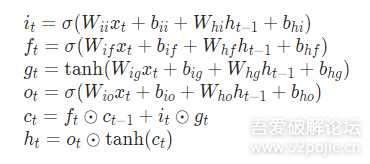
图4.png
W和b都是LSTM待学习的参数,具体参数细节可以参考pytorch的官方文档。
指令嵌入
指令嵌入的目的是也为了获得指令的向量化表示,方便LSTM等其它模型进行计算。这里使用word2vec的skip-gram模型实现。word2vec是谷歌公司开源的一个用于计算词嵌入的工具,包含cbow和skip-gram两个模型。指令嵌入具体实现细节如下:
(1)操作码、寄存器、加减乘符号以及中括号都看成一个词。比如mov dowrd ptr [0x123456+eax*4], ebx这条指令可以得到mov,dowrd,ptr,[,0x123456,+,eax,*,4,],ebx。然后这条指令看成一个句子送入word2vec进行训练,进而得到每一个词的向量化表示。
(2)为了减小词库的大小。操作数中超过0x5000的数值用mem,disp,imm代替
[0xXXXXXXXX] -> [mem][0xXXXXXXXX + index*scale + base] -> [disp + index*scale + base]0xXXXXXXXX -> imm(3)指令向量由一个操作码对应的向量和两个操作数对应的向量三部分组成,操作数不够的指令添加0向量补齐。对于超过两个操作数的指令,则最后两个操作数的向量求和取平均。操作数里面有多个词的情况下,各个词向量求和取平均表示当前操作数的向量。
代码实现
模型的代码实现用的是深度学习框架pytorch,word2vec的实现用的gensim库。word2vec的调用参数在insn2vec.py实现如下:
model = Word2Vec(tokensList, vector_size=wordDim, negative=15, window=5, min_count=1, workers=1, epochs=10, sg=1) model.save('insn2vec.model')tokensList的元素是一个列表,保存的是一条指令分词(tokenization)后的各个词序列。word2vec训练完成后保存到insn2vec.model文件,方便后续进行进一步的微调。
指令嵌入的实现在lstm.py文件中,实现如下:
class instruction2vec(nn.Module): def __init__(self, word2vec_model_path:str): super(instruction2vec, self).__init__() word2vec = Word2Vec.load(word2vec_model_path) self.embedding = nn.Embedding.from_pretrained(torch.from_numpy(word2vec.wv.vectors)) self.token_size = word2vec.wv.vector_size#维度大小 self.key_to_index = word2vec.wv.key_to_index.copy() #dict self.index_to_key = word2vec.wv.index_to_key.copy() #list del word2vec def keylist_to_tensor(self, keyList:list): indexList = [self.key_to_index[token] for token in keyList] return self.embedding(torch.LongTensor(indexList)) def InsnStr2Tensor(self, insnStr:str) -> torch.tensor: insnStr = RefineAsmCode(insnStr) tokenList = re.findall('\w+|[\+\-\*\:\[\]\,]', insnStr) opcode_tensor = self.keylist_to_tensor(tokenList[0:1])[0] op_zero_tensor = torch.zeros(self.token_size) insn_tensor = None if(1 == len(tokenList)): #没有操作数 insn_tensor = torch.cat((opcode_tensor, op_zero_tensor, op_zero_tensor), dim=0) else: op_token_list = tokenList[1:] if(op_token_list.count(',') == 0): #一个操作数 op1_tensor = self.keylist_to_tensor(op_token_list) insn_tensor = torch.cat((opcode_tensor, op1_tensor.mean(dim=0), op_zero_tensor), dim=0)#tensor.mean求均值后变成一维 elif(op_token_list.count(',') == 1): #两个操作数 dot_index = op_token_list.index(',') op1_tensor = self.keylist_to_tensor(op_token_list[0:dot_index]) op2_tensor = self.keylist_to_tensor(op_token_list[dot_index+1:]) insn_tensor = torch.cat((opcode_tensor, op1_tensor.mean(dim=0), op2_tensor.mean(dim=0)), dim=0) elif(op_token_list.count(',') == 2): #三个操作数 dot1_index = op_token_list.index(',') dot2_index = op_token_list.index(',', dot1_index+1) op1_tensor = self.keylist_to_tensor(op_token_list[0:dot1_index]) op2_tensor = self.keylist_to_tensor(op_token_list[dot1_index+1:dot2_index]) op3_tensor = self.keylist_to_tensor(op_token_list[dot2_index+1:]) op2_tensor = (op2_tensor.mean(dim=0) + op3_tensor.mean(dim=0)) / 2 insn_tensor = torch.cat((opcode_tensor, op1_tensor.mean(dim=0), op2_tensor), dim=0) if(None == insn_tensor): print("error: None == insn_tensor") raise insn_size = insn_tensor.shape[0] if(self.token_size * 3 != insn_size): print("error: (token_size)%d != %d(insn_size)" % (self.token_size, insn_size)) raise return insn_tensor #[len(tokenList), token_size] def forward(self, insnStrList:list) -> torch.tensor: insnTensorList = [self.InsnStr2Tensor(insnStr) for insnStr in insnStrList] return torch.stack(insnTensorList) #[insn_count, token_size]