批量将下载的公众号文章html转pdf,合并pdf文件
(编辑:jimmy 日期: 2026/7/14 浏览:3 次 )
最近用python写了个html转换工具html2pdf.exe https://wwk.lanzouf.com/iSpV90fbtpqh ,代码如下:
[Asm] 纯文本查看 复制代码
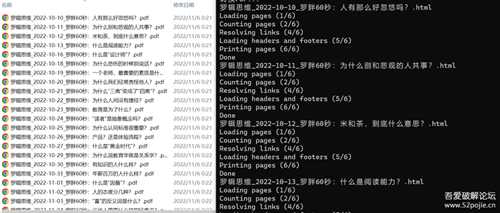
工具依赖wkhtmltopdf,先从https://wkhtmltopdf.org/downloads.html 下载,然后将wkhtmltopdf.exe加入环境变量,直接运行html2pdf.exe,导出的pdf文件在pdf目录:
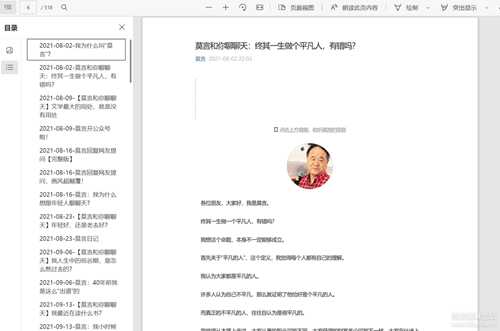
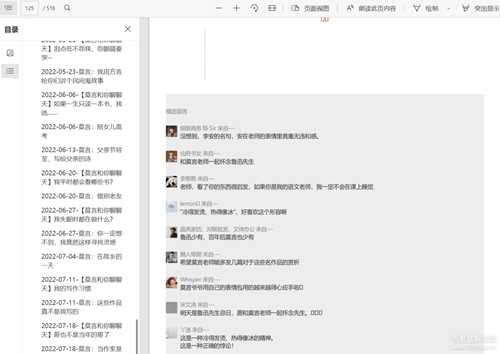
然后用这个pdf合并工具 https://wwn.lanzouf.com/irAGD089czyj 将所有pdf合成一个文件,比如我将莫言老师的所有文章合成了一个pdf文件,看文章方便多了:
[Asm] 纯文本查看 复制代码
def to_pdf(): import pdfkit htmls = [] for root, dirs, files in os.walk('.'): for name in files: if name.endswith(".html"): print(name) try: pdfkit.from_file(name, 'pdf/'+name.replace('.html', '')+'.pdf') except Exception as e: print(e)
工具依赖wkhtmltopdf,先从https://wkhtmltopdf.org/downloads.html 下载,然后将wkhtmltopdf.exe加入环境变量,直接运行html2pdf.exe,导出的pdf文件在pdf目录:
然后用这个pdf合并工具 https://wwn.lanzouf.com/irAGD089czyj 将所有pdf合成一个文件,比如我将莫言老师的所有文章合成了一个pdf文件,看文章方便多了:
下一篇:APTV-支持 iOS、iPadOS、tvOS、macOS的直播流播放器